总体分布的非参数估计
--Parzen窗估计
好久都没有更新了,最近有些忙,上周抽时间研究一些非参数估计的内容,终于解决了以前一直不太明白的问题,以前上模式识别课的时候觉得好麻烦,这次认真推导了一边,发现原来虽然复杂,但实际上应用起来却很简单~果然简单才是最美~
本文为个人理解,若有什么不对的地方欢迎指正,一起交流进步~
1 为什么要用非参数估计的方法:
对于某些数据,我们可以采用已知的模型对数据样本进行匹配,例如利用高斯模型对图像中的像素进行估计,由于我们预估图像的像素的分布是又由一个或者多个不同的高斯函数叠加而成,因此我们只需要对高斯函数的参数确定,便可以得到相应的模型,此时我们的目的是利用数据估计参数。 当我们不确定数据的分布情况时,我们无法通过将观测数据转换成参数,为了得到一些未知点的贝叶斯概率,我们仍然需要判断总体分布的情况,因此提出了某些直接用样本来估计总体分布的方法,称其为估计分布的非参数法。
2 基本原理介绍:
简单来说(不是严格定义)对某些样本例如{x,y,z}进行估计时,对于数据x,我们以x为中心,将宽度为h内的所有数据都包含到,例如里中心点x越大的数据贡献越大,越远贡献越小,将这些贡献相加后,我们将此值视为此点的密度p(x);,在对所有点进行计算后,我们可以得到总体的概率密度分布。
注:对于来自单个类的样本,最终估计的值为类条件概率密度;若样本来自于多个类,其估计的值为混合密度。
3 非参数估计的基本思想
由2基本原理可知,我们是利用点在某个区域的贡献进行估计的,因此此类算法最基本的出发点是:随机向量x落入到区域R的概率P为:
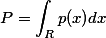
同时,对于由于随机向量之间是相互独立的,因此对于N个向量x,x1,….,xN,中有k个落入区域R中的概率Pk符合二项分布。由二项分布的性质可以知道:
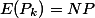
以及当:
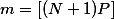
时Pk取得最大值,由此可以得到,抽取N个样本时,k=m个落入区域R的概率最大,最大值为P,由此可以写出:
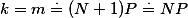
即:
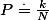
此处与似然函数的思想有些类似,即由于随机抽取N个样本,有m个落入区域R的概率最大(为P),因此对于某次观测,我们观测到恰好有k个落入区域R中,那么我们就认为k就是m,因而k/m即为概率P的估计值。
当我们得到某点的概率估计值时,由上所述,我们可以认为这是一个很好的估计,但是对于单个点的概率对我们而言是没用的,我们要估计出其整体的分布来,因此我们将对第一个公式加强条件,进行变形:
首先对于概率密度函数p(x)我们认为它是连续的,这个性质非常重要;
其次我们将对公式中的积分区域R进行限制,我们将R限制为一个非常小的区域,由于p(x)是连续的,因此必然可以使得p(x)在这个区域内几乎不发生变化,那么公式一将变为:
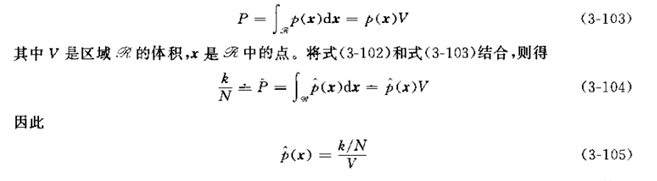
因此我们可以得到x点的概率密度的估计值,可以看到,这个值与样本个数K,区域大小V,落入区域中的k有着关系。此式虽然简单,但是仍然存在这一些缺陷:
(1)由3-105式我们可以自然的相处,当我们选取一个固定的V,然后无限的增大样本N,此时会发生什么情况呢?随着样本数的增加,k/N逐渐趋于稳定,我们将得到这个空间V的一个平均估计。
(2)若我们不想得到这个平均的估计,我们可不可以将V不断的缩小?当然可以,但是随着V的缩小,最后可能会出现这个区域V中任何一个样本都不包括,最终导致估计值为0,没有任何意义
为了弥补这样的缺陷,我们对其进行改进,使其满足一些很好的性质:
首先假设样本空间无限大,我们构造一串包含不同大小区域的一个序列,每个区域进行一次估计值,可以得到:
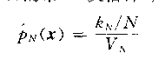
这是对序列中Vn区域进行的估计,并且此时要满足:
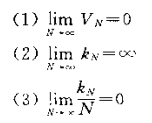
条件1可以使得区域平滑的缩小,使得概率密度在x点连续;
条件2使得随着样本的增多,概率收敛于P
条件3表明尽管在一个足够小的区域中落入了大量的样本,但是对于整体的样本个数是微不足道的(是否使其满足概率密度函数的性质?)
由此我们引入了Parzen窗估计:
如上所述。
Parzen窗估计
首先我们假设V是一个超立方体,那么其体积为:
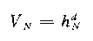
其中h为窗宽,d为维度。定义超立方体的窗函数为
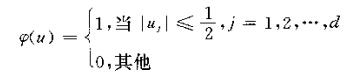
那么落入超立方体的样本数kn可表示为:
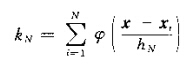
那么估计函数可以表示为:
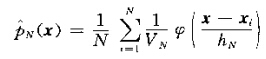
为了保证,此估计是一个合理的估计,窗函数应当满足:
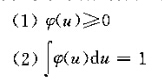
可保证估计出的概率密度函数满足性质。
因此窗函数的选取不是固定的,可以选取多种不同的函数,例如正态窗函数,指数窗函数等。
窗宽h对估计造成的影响:窗宽越大估计越平均,窗宽越窄,估计出来的波动会变大
实例
以一维数据为例,选择正态窗函数,则:
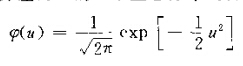 (1)
(1)
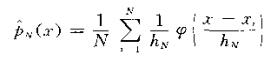 (2)
(2)
其中:
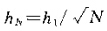 (3)
(3)
可以看到hn是满足我们之前所为了改进性质所提出的条件1,即将区域逐渐缩小。
在算法上实现比较简单,首先确定窗函数及各个公式,其次将参数调整好,可以看到在上式中,对于每个点x我们都将进行一次计算,因此若要进行仿真作图计算,计算量将会比较大。
但由于我们采用的为正态窗函数,可以先进行预处理,将正态函数的值求出,然后采用查表的方式提高算法的计算速度,用空间换取时间。
参考文献:
[1] 边肇祺, 张学工. 模式识别[M]. 清华大学出版社有限公司, 2000.